Why Anti-Scraping Measures Are Escalating in 2026
Social media platforms have spent the last 18 months aggressively tightening their anti-scraping defenses — and 2026 is when the consequences are really showing up. Twitter has tiered API pricing that prices out most independent developers. Reddit’s API changes forced dozens of third-party apps to shut down.
LinkedIn has taken legal action against scrapers and set precedents for enforcement. IP banning, CAPTCHA systems, behavioral analysis, and machine learning-based bot detection are now standard. The platforms that were easy to scrape two years ago have become significantly more difficult, and the tools that were working then often are not working now.
What the Professionals Are Using Instead
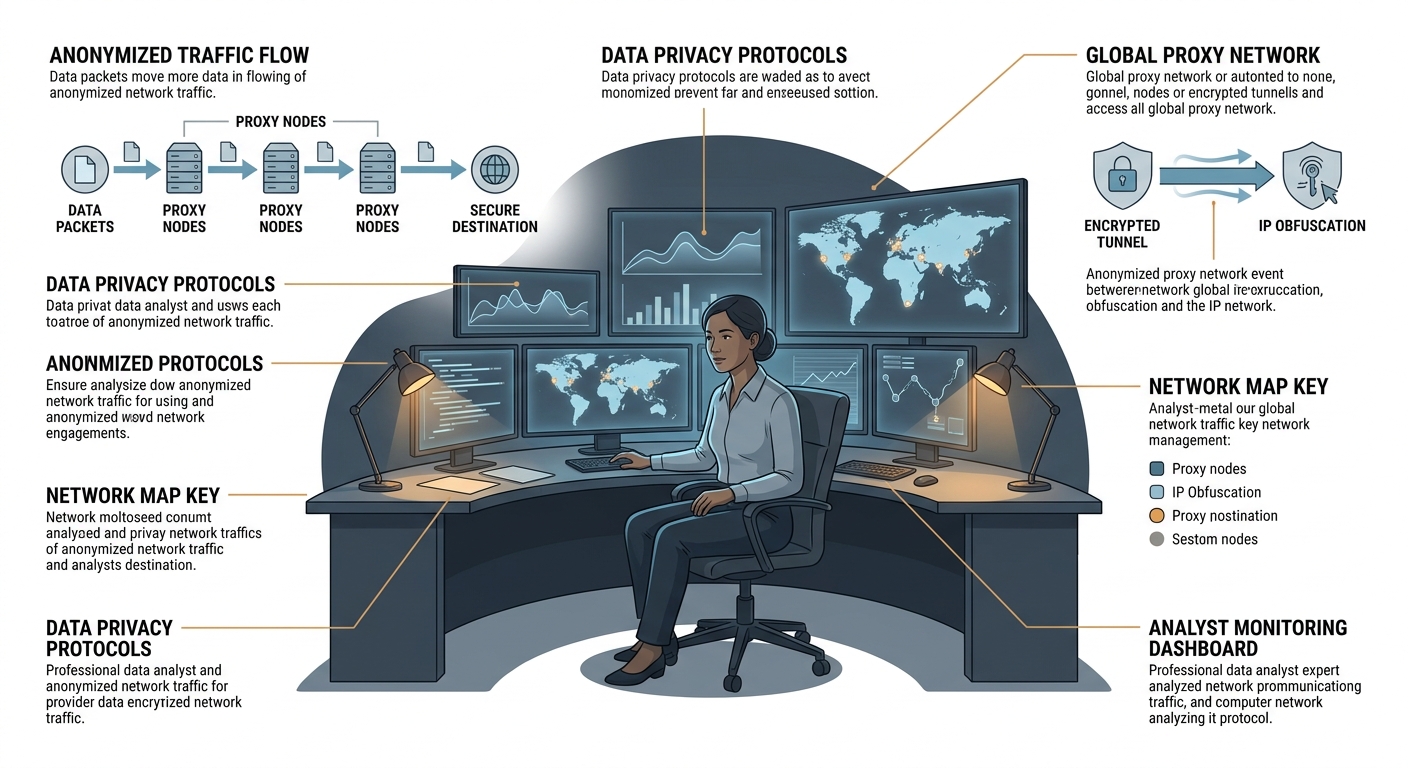
The teams still collecting social data reliably in 2026 are using a combination of residential and mobile proxies, antidetect browsers, and managed scraping APIs that handle browser fingerprinting and block evasion automatically. Mobile proxies from real carrier networks — 3G, 4G, 5G — carry the highest trust scores and are the hardest for detection systems to flag. For teams doing brand monitoring, competitor tracking, or sentiment analysis at scale, the investment in quality proxy infrastructure is no longer optional.
Tools like Bright Data, Decodo, and Oxylabs have built specialized social media scraping APIs that manage the detection layer so data teams can focus on the analysis rather than the infrastructure battle.
AI-Native Extractors Are Replacing Traditional Scrapers — And It Is Happening Fast
The Problem With Old-School Selector-Based Scrapers

Traditional web scrapers break every time a website updates its HTML structure. A site redesign, a class name change, a layout shift — and your scraper stops working until someone manually fixes the selectors. For teams running continuous data collection pipelines, this maintenance overhead is expensive and unpredictable. The bigger the scraping operation, the more engineering time gets consumed just keeping existing scrapers alive rather than building new ones.
How AI-Native Extraction Changes the Game
AI-native extractors understand the meaning of the data they are looking for — not just its position in the HTML. That means they stay functional when the page layout changes because they are looking for the concept, not the container. In 2026, this is moving from experimental to production-ready for many use cases. E-commerce price monitoring, travel data collection, news aggregation, and SERP tracking are all areas where AI-native extraction is already proving more reliable than traditional selector-based approaches.
Teams that adopt this infrastructure now are building pipelines that require significantly less maintenance over time — which at scale translates directly into lower operational cost and faster data delivery.
Quick Links: