The Orbital AI Data Center Story Nobody Is Talking About
SpaceX’s S-1 prospectus filed on May 20 disclosed that “most of SpaceX’s capital expenditures in the first quarter were for AI.” Elon Musk controls 85% of voting power, and the filing notes a total addressable market of $28.5 trillion — most of which is outside SpaceX’s current business. The part buried in analyst commentary: the $1.75 trillion valuation implicitly prices speculative future projects including orbital AI data centers.
The idea of putting compute infrastructure in orbit — zero cooling costs, abundant solar power, direct latency to Starlink terminals — is being treated as a legitimate near-term possibility by institutional investors pricing the deal. For data infrastructure specialists, the orbital compute trajectory is worth tracking now rather than when it is mainstream.
What the AI Infrastructure Build-Out Means for Scraping and Data Collection
Nvidia’s $75.2 billion data center quarter and SpaceX’s AI capex disclosure are both indicators of the same thing: AI infrastructure investment is at a scale that is rapidly improving the capability of every system that uses it — including the bot detection systems that web scrapers and data collection pipelines have to navigate.
Every major platform — Amazon, Cloudflare, DataDome — is running its bot detection on AI infrastructure that is getting more capable every quarter at the same cost. The arms race between sophisticated scraping tools and sophisticated detection systems is accelerating on both sides. For teams running data collection at scale, this is not a future concern — it is a [Year] operational reality that requires continually updating your infrastructure rather than treating any current setup as permanently reliable.
Nvidia’s $75 Billion Data Center Quarter Is Reshaping What AI-Powered Web Data Collection Can Do
The Compute Capacity Behind the Tools That Are Changing Data Collection
Nvidia’s data center revenue of $75.2 billion for Q1 [Year] represents the compute capacity being deployed to power AI systems across every industry. For web scraping and data collection, this has a direct impact that is easy to miss: AI-native extractors — tools that understand the meaning of data they are looking for rather than just its position in the HTML — are becoming production-ready because the AI infrastructure supporting them is now abundant and cheap enough to run at scale.
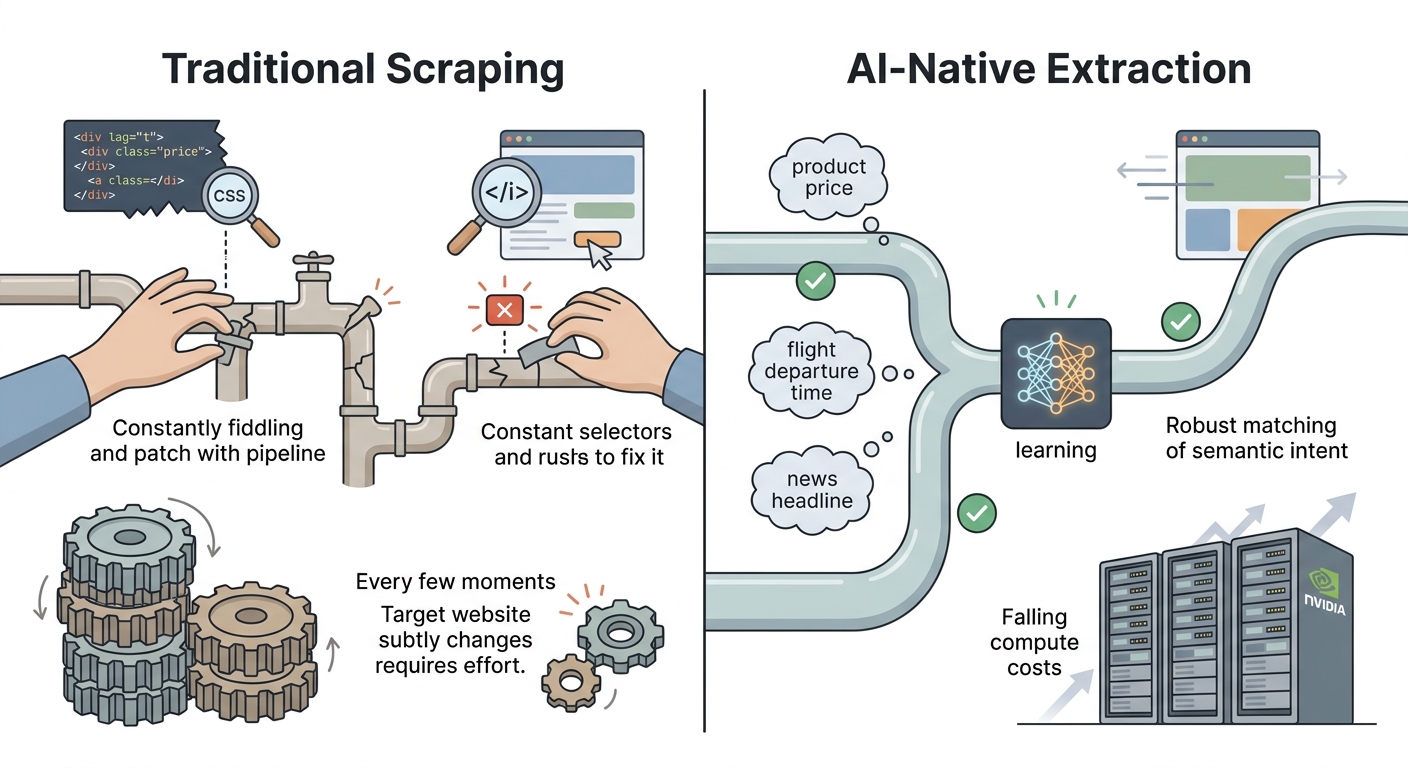
Traditional selector-based scrapers break every time a website updates its HTML structure. AI-native extractors understand what they are looking for conceptually and stay functional through layout changes because they are matching concepts, not containers.
Why This Quarter Is the Right Time to Evaluate Your Scraping Infrastructure
For data engineering teams still running traditional selector-based scraping pipelines, Q2 [Year] is a natural evaluation point. The AI-native extraction tools that were experimental 18 months ago are now production-tested at scale for e-commerce price monitoring, travel data collection, and news aggregation.
The maintenance cost difference is measurable: traditional scraping requires constant selector updates as sites change; AI-native extraction requires significantly less maintenance because it is matching semantic intent rather than specific HTML patterns. At enterprise scale, that maintenance delta translates directly into engineering cost and pipeline reliability.
The Nvidia infrastructure build-out means the compute cost of running AI extraction is continuing to fall — making the switch from traditional to AI-native extraction economically clearer every quarter.
Quick Links: