Looking for a detailed Bright Data Scraping Browser Review, Don’t worry I got you covered.
The internet is an enormous pool of data that can be incredibly valuable for businesses, researchers, and individuals. However, accessing this data can be a daunting task, especially when it comes to data scraping.
Data scraping is the process of extracting data from websites automatically, and it is often used for research, marketing, and other purposes.
Data scraping can be done manually, but this is a time-consuming process and requires a lot of technical expertise.
Fortunately, there are software tools and services available that can automate the data scraping process and make it easier to access the data you need.
But, it can also be challenging, especially when dealing with site blocks, CAPTCHA, and other bot detection scripts. The average total cost of a data breach is $3.62 million in 2017, a decrease of 10 percent over last year.
That’s where the Bright Data Scraping Browser comes in. So, let us discuss in detail about how the Bright Data Scraping Browser helps you in data scraping in our detailed Bright Data Scraping Browser review.
What Is Bright Data Scraping Browser?
The Bright Data Scraping Browser is an all-in-one automated browser designed specifically for data scraping purposes.
It is powered by an award-winning proxy network that offers over 72 million IPs and the ability to target any country, city, carrier & ASN.
This premium proxy service is a top choice for developers who need to scrape data at scale. Moreover, it is Puppeteer compatible, which means it is more powerful than automated and headless browsers.
The Bright Data Scraping Browser is designed to make data scraping fast, easy, and secure. It uses advanced technologies such as AI-driven captcha and bot detection that ensures smooth data extraction.
With the Bright Data Scraping Browser, users can quickly and securely extract data from any website without any hassle.
Features Of Bright Data Scraping Browser
Bright Data’s scraping browser offers a number of features designed to help with Web Scraping at scale.
1. Automatic management of website unlocking operations
The program has a key feature of automatic management of website unlocking operations. This includes solving CAPTCHAs, fingerprinting browsers, and a variety of other tasks.
This can save time and resources for developers who need to scrape large amounts of data from websites.
2. Outsmart bot-detection software
Another important feature of Bright Data’s scraping browser is its ability to outsmart bot-detection software.
In addition to bypassing bot-detection systems using AI technology, scrapers can also produce better unlocking rates when using proxies instead of AI technology.

3. Highly scalable
Bright Data’s scraping browser is also highly scalable, allowing developers to grow their scraping projects with as many browsers as they need.
The browsers are hosted on Bright Data’s infrastructure, which is designed to handle large amounts of traffic and requests.
4. Compatible with both Puppeteer (Python) and Playwright (Node.js)
Finally, Bright Data’s scraping browser is compatible with both Puppeteer (Python) and Playwright (Node.js), which allows developers to interact with browser sessions and perform website interactions to retrieve data.
This can be useful for scraping projects that require clicking buttons, scrolling, or adding text to web pages.
Bright Data Scraping Browser Review: Pricing
The pricing of the Bright Data Scraping Browser is designed to be flexible and accessible to businesses of all sizes, from small startups to large enterprises.
The company offers four pricing tiers, including Pay As You Go, and the other three, to meet the needs of different users.
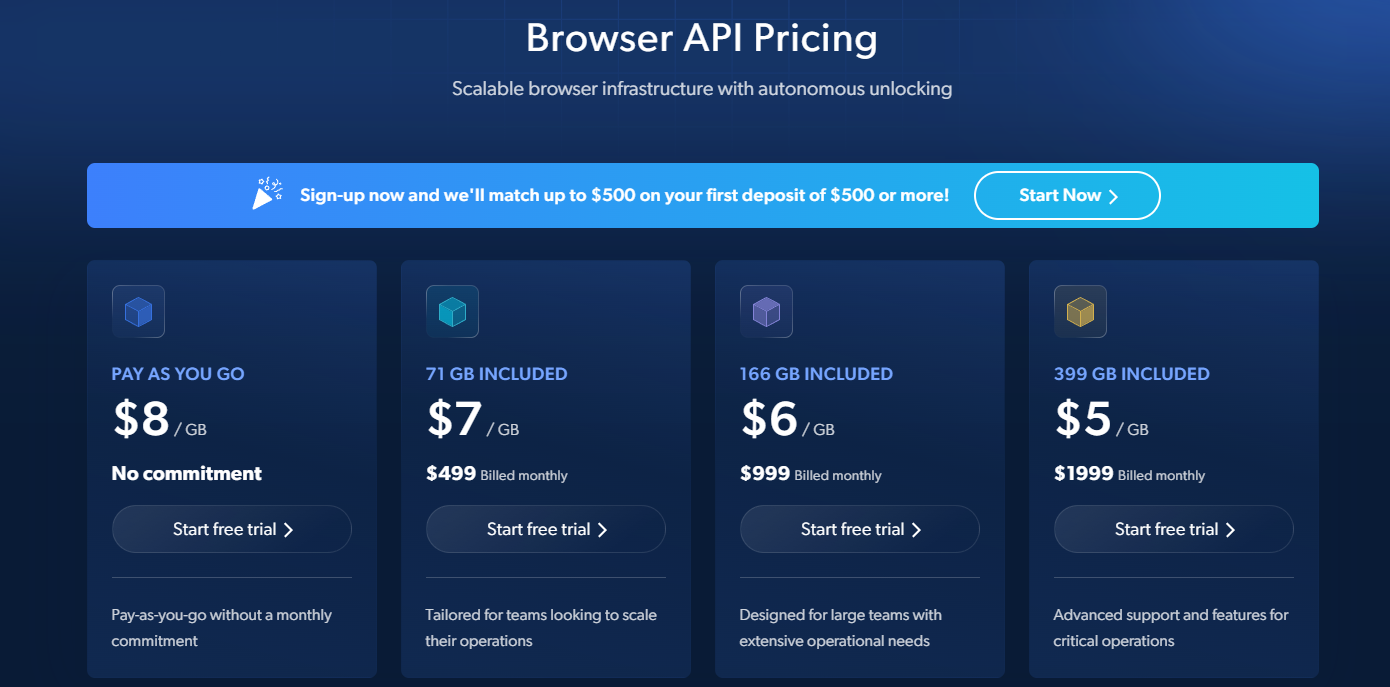
- Pay As You Go: $8 per GB
- No monthly commitment; ideal for occasional or small-scale scraping.
- 71 GB Included: $7 per GB ($499 billed monthly)
- Tailored for teams looking to scale their operations with moderate volume needs.
- 166 GB Included: $6 per GB ($999 billed monthly)
- Designed for large teams and organizations requiring extensive browser scraping capabilities.
- 399 GB Included: $5 per GB ($1,999 billed monthly)
- Advanced support and premium features for critical, high-volume web scraping operations.
All plans include access to scalable browser infrastructure with autonomous unlocking and a free trial offer.
How Scraping Browsers Outperforms Headless Browsers?
Scraping Browser, a GUI (Graphical User Interface) browser, outperforms headless browsers in several ways when it comes to scaling data scraping projects and bypassing blocks.
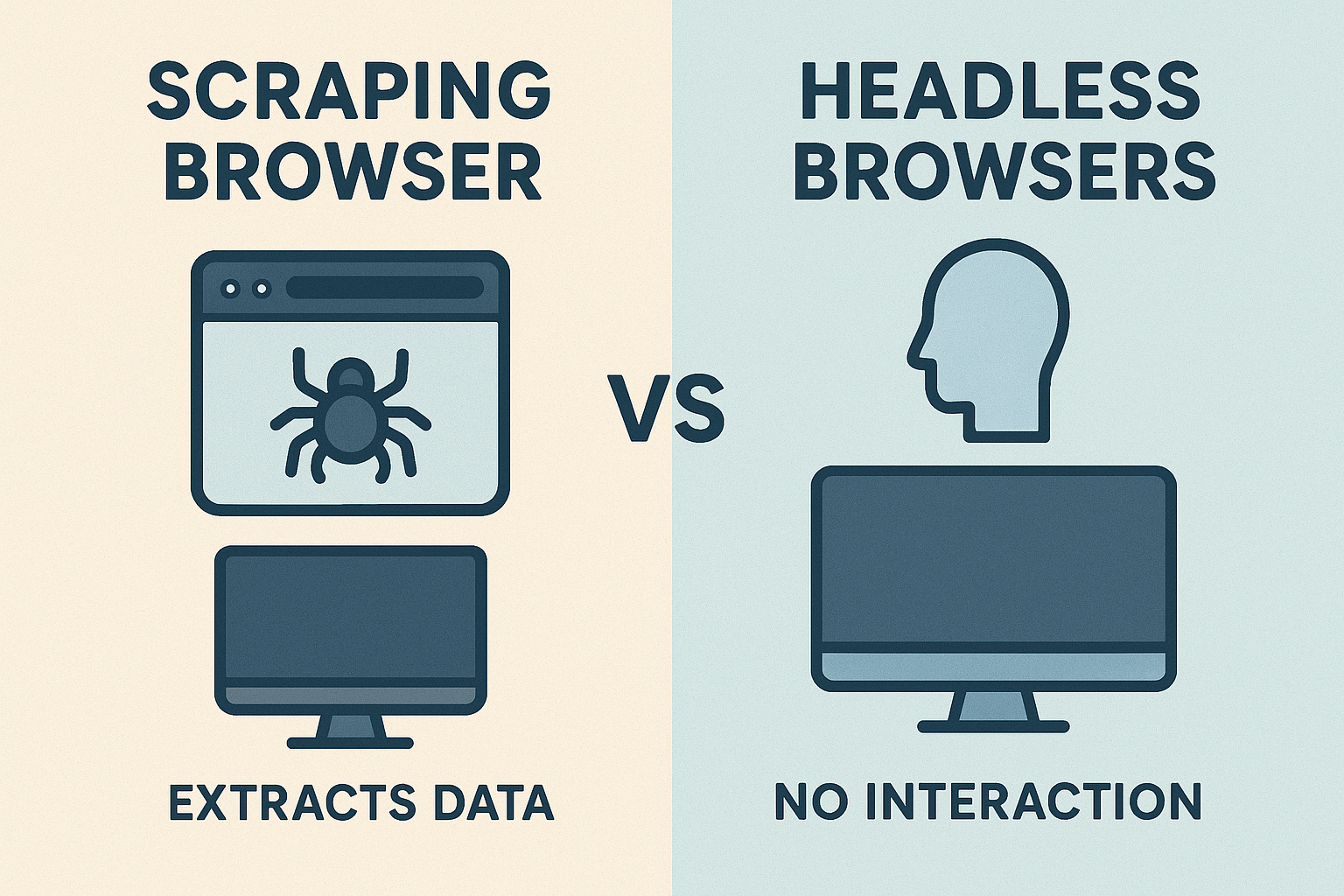
1. Bypassing Bot Detection Software
Bot detection software is becoming more and more sophisticated, making it difficult for developers to scrape data from websites.
Bot detection software is easily able to detect headless browsers, which are commonly used to scrape the web.
However, Scraping Browser is less likely to be detected because it uses a GUI interface, which makes it appear more like a real user browser.
This means that developers can use Scraping Browser to scrape data without worrying about being detected and blocked.
2. Built-In Website Unlocking Functions
Website blocks are automatically unlocked by Scraping Browser. These functions include solving CAPTCHAs, fingerprinting browsers, automatically retrying, selecting headers, and cookies, and rendering JavaScript.
This means that developers do not have to spend time and resources manually unlocking websites or finding workarounds for blocked content. Scraping Browser takes care of it all automatically.
3. Easy to Scale
Scraping Browser is hosted on Bright Data’s servers, which means that developers can easily scale their web scraping projects by opening as many Scraping Browsers as they need without having to invest in expensive in-house infrastructure.
This makes it easy to manage large data scraping projects and ensures that developers can access the data they need quickly and efficiently.
4. Ability to Interact with Websites
A scraping Browser is a GUI browser, which means that developers can use it to interact with websites in ways that are not possible with headless browsers.
For example, developers can hover over pages, click buttons, scroll, and add text. This makes the Scraping Browser an ideal choice for web scraping projects that require website interactions to retrieve data.
5. Enhanced Debugging Capabilities
Scraping Browser provides enhanced debugging capabilities compared to headless browsers.
Developers can use the GUI interface to see what is happening on the website in real time and can easily identify any issues or errors that occur during the scraping process.
This makes it easier to troubleshoot problems and ensure that the data is being scraped correctly.
FAQs On Bright Data Scraping Browser Review 2026
When projects involve websites employing advanced JavaScript, strict bot detection, and complex user interaction scenarios.
Yes. Fully compatible with Puppeteer and Playwright, allowing maximum control using popular programming languages.
Yes, its automated CAPTCHA solving drastically reduces manual interventions and blocking issues.
Absolutely. It’s hosted on Bright Data’s cloud infrastructure, allowing elastic scaling on-demand.
It mimics real user browsing with GUI, bypassing common anti-bot measures undetectable by headless browsers.
Quick Links:
Conclusion: Bright Data Scraping Browser Review 2026
The Bright Data Scraping Browser represents the future of web scraping, conquering the toughest technical barriers—bot detection, CAPTCHAs, scaling—through automated, cloud-based, user-like browsing. For teams and developers looking to elevate their data scraping projects, reduce maintenance overhead, and unlock access to previously difficult sources, this tool is unmatched in 2026.
Leveraging the powerful features, seamless framework compatibility, and flexible pricing options outlined in this Bright Data Scraping Browser Review, professionals can confidently scale their data-driven applications and research with minimal fuss.
For those serious about scraping success and efficiency at scale, Bright Data’s Scraping Browser is a must-try solution.