The Model Abundance Problem
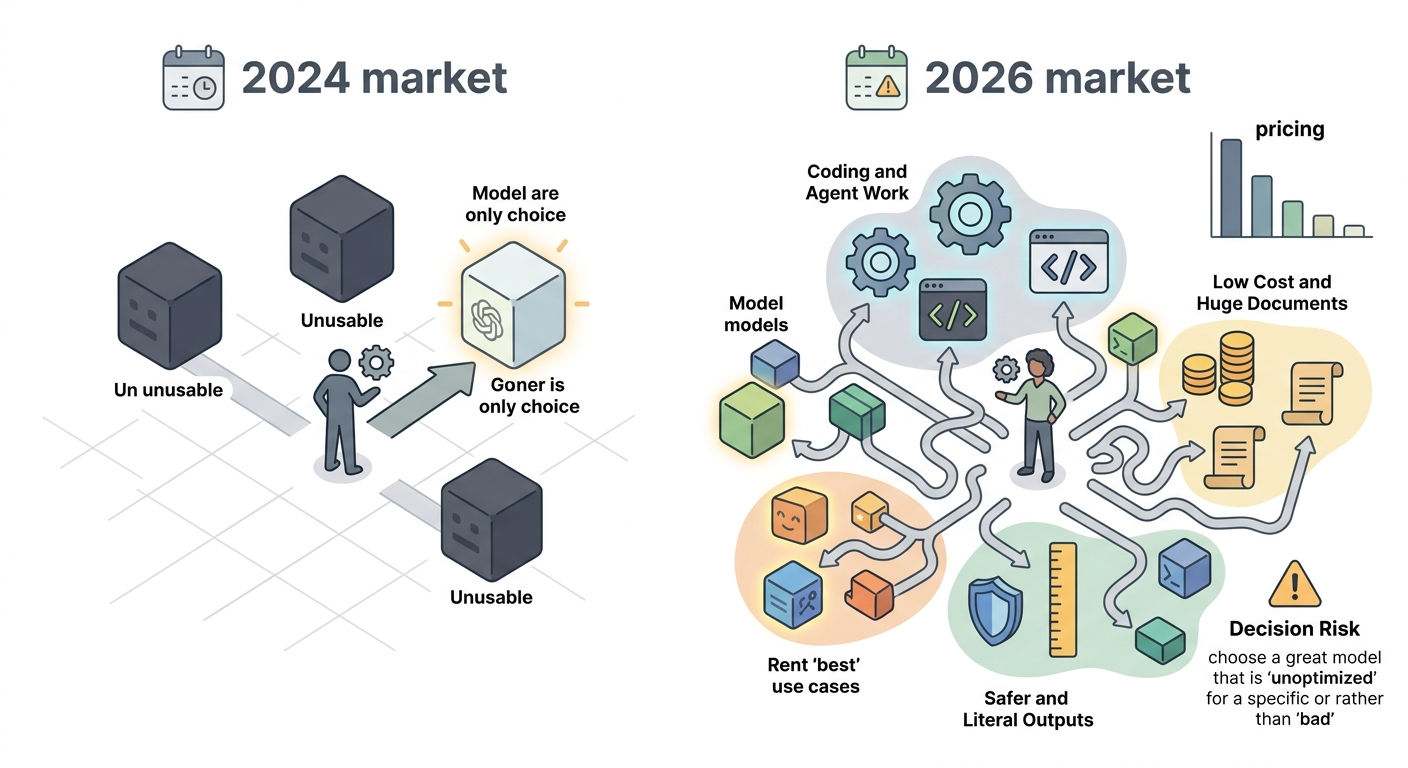
The AI model market in 2026 has the opposite problem from two years ago. In 2024, founders had limited choices and most decisions were obvious. In 2026, the number of capable models has exploded, pricing has dropped dramatically, and the meaningful differences between top models are increasingly task-specific rather than universal. Choosing the wrong model for your startup’s core use case is now a real product risk — not because any of the options are bad, but because they are optimized for different things.
OpenAI’s GPT-5.5 pushes deeper into coding and agent-style work. DeepSeek V4 attacks on price and long context. Anthropic Opus 4.7 and now 4.8 stand out for safer, more literal outputs. Your biggest benefit is better buying power — you now have clearer choices: GPT-5.5 for coding and work tasks, DeepSeek V4 for low-cost bulk use and huge documents, and Claude Opus for regulated or instruction-sensitive work. Price and workflow matter more than benchmark scores.
Breaking Down the Three Main Choices
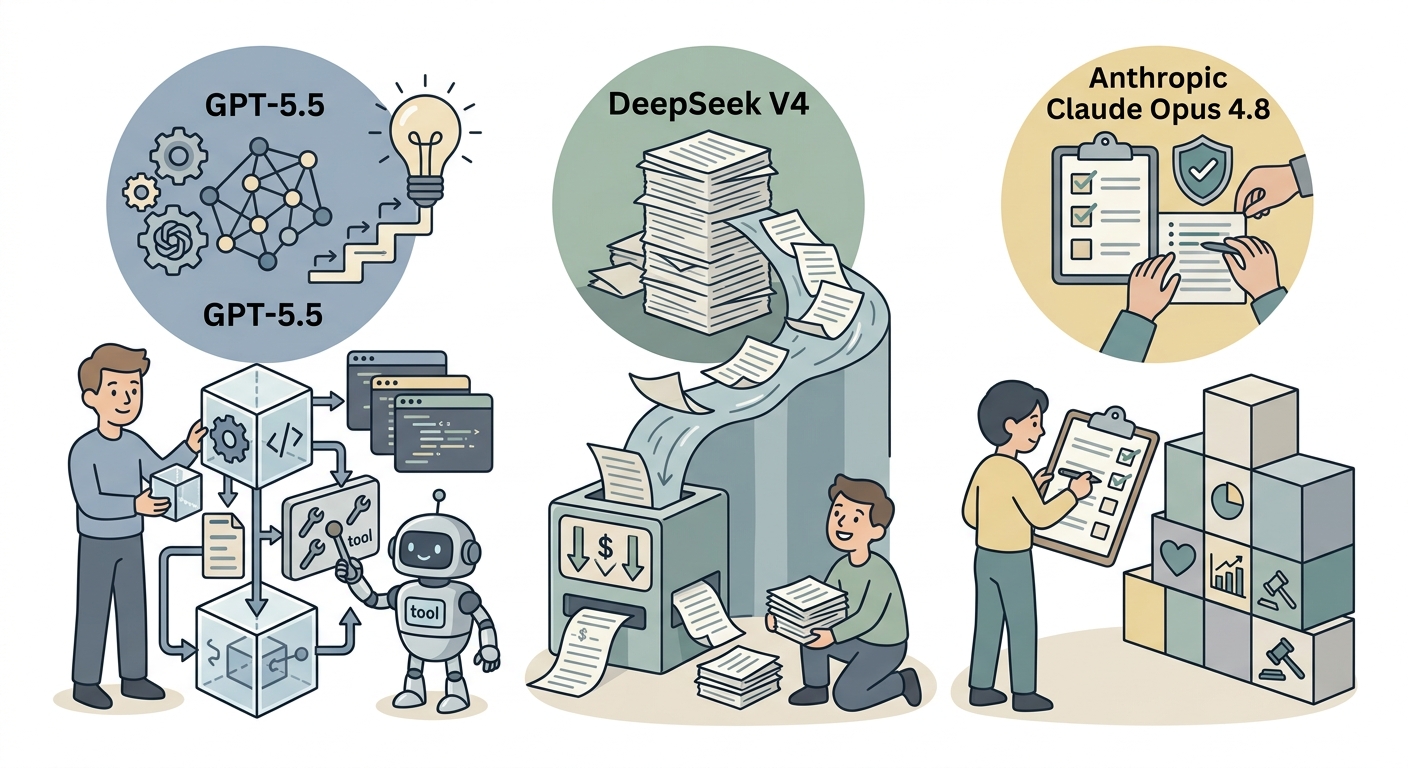
GPT-5.5 is the strongest option for startups building coding assistants, developer tools, or agent workflows that need to take complex multi-step actions reliably. OpenAI has invested heavily in the agentic capability of this model and it shows in production use cases that require reasoning over code and executing sequences of tool calls.
DeepSeek V4’s one million token context window combined with aggressive pricing makes it the right choice for document-heavy workflows where you are processing large volumes of text and need to keep costs manageable. If your startup is building in legal tech, compliance, research, or any domain with long documents, DeepSeek’s context-cost combination is hard to beat at scale.
Claude Opus 4.8 is the choice for applications where instruction-following precision and output reliability matter more than raw capability. Regulated industries — healthcare, finance, legal — where outputs need to be predictable, literal, and aligned with specific guidelines are where Anthropic’s safety-first design philosophy creates a measurable product advantage.
The Decision Framework
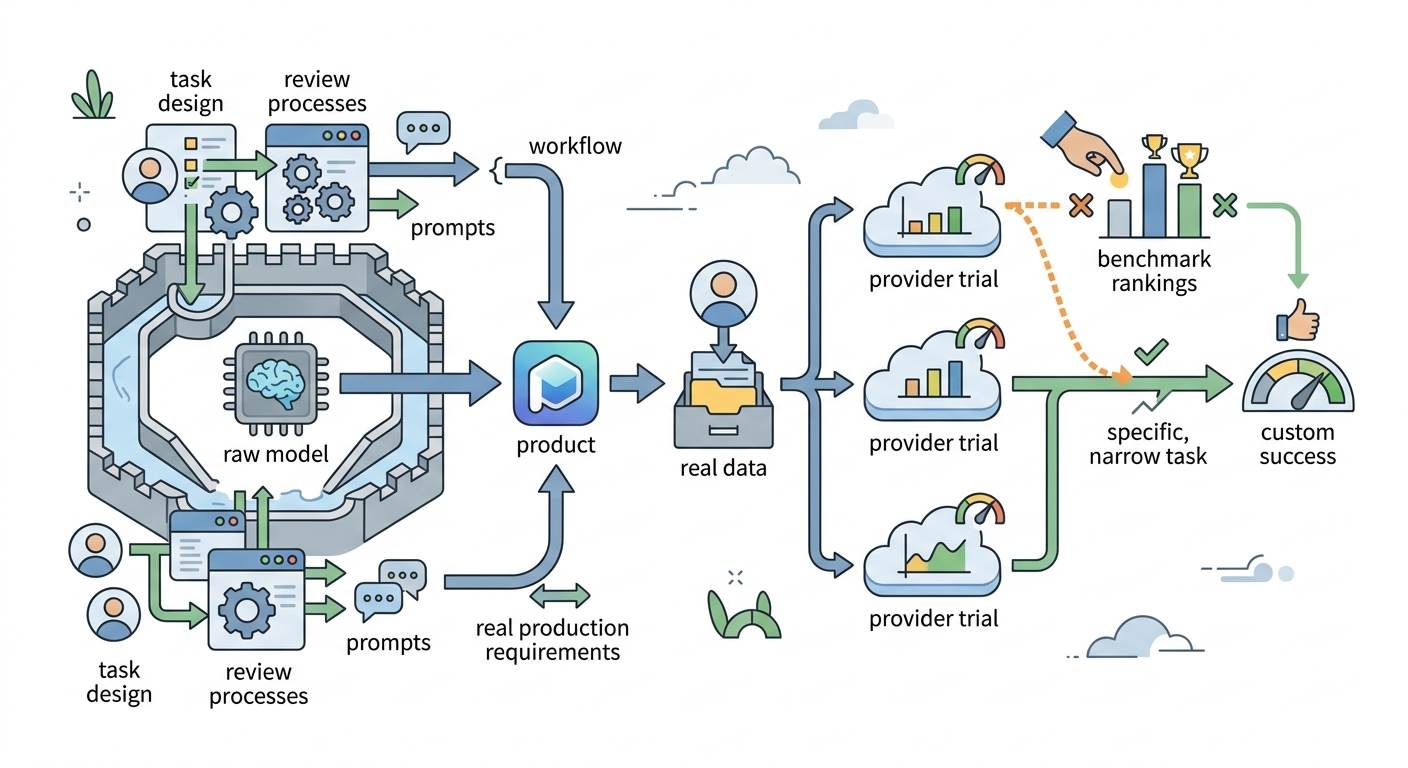
Your moat is not the raw model — it is the system around it: task design, prompts, review processes, and the specific workflow you build. Switching models later is possible but costly. Pick based on your actual production requirements, not benchmark rankings that may not reflect your use case.
Test on real data from your target use case before committing. Every major provider offers trials. The model that scores highest on published benchmarks is rarely the model that performs best on the specific, narrow task your startup actually needs it for.
💬 Reddit — r/Machine Learning comparisons of GPT-5.5, Claude Opus, Deep Seek V4: 🔗https://www.reddit.com/r/MachineLearning/search/?q=GPT5.5+Claude+DeepSeek+comparison+2026
🐦 X/Twitter — founder model selection discussions post-I/O 2026: 🔗https://x.com/search?q=GPT+5.5+vs+Claude+Opus+4.8+startup+2026&f=live
💬 Quora — which AI model is best for building a startup in 2026: 🔗https://www.quora.com/search?q=best+AI+model+for+startup+GPT+Claude+2026
Quick Links: